Machine-Learing:集成学习-stacking
- Qingfeng Zhang
- Machine learning
- October 14, 2020
Sections
集成学习的思想是通过合并多个模型来提升机器学习的学习性能;
集成学习的方法可分为3种:Bagging,Boosting,Stacking;
bagging用于减小方差;
boosting用于减少偏差;
stacking有助于提升预测结果
1.stacking的思想
- stacking是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术;
- 基础模型利用整个训练集进行训练,元模型将基础模型的特征作为特征进行训练;
- 基础模型通常包含不同的学习算法,因此stacking通常是”异质集成“的;
Otto Group
Product分类挑战赛中,第一名的获得者通对30个模型进行stacking,将30个模型的输出作为特征,继续在XGboost,Meural
Network和Adaboost中进行训练,最后加权平均得到最后的结果;
Kaggle上关于stacking的一个分享 https://www.kaggle.com/c/otto-group-product-classification-challenge/discussion/14335
2.stacking的框架流程
stacking用到了交叉验证的思想,假设使用5折交叉验证,stacking的框架如下:
- 选择一个基模型;
- 把训练数据集分为不交叉的5份,记为train1到train5;
- 分别把train1到train5作为测试集,其他的数据作为训练集,使用训练的模型分别对train1到train5进行预测,得到5个预测结果,这5个结果可以拼成与原始train长度相等的数据,将其作为第一个基模型对train数据集的一个stacking转换;
- 将上述的5个模型分别对test数据集进行预测,也得到5个预测结果,取5个结果的平均值,将其作为第一个基模型对test数据集的一个stacking转换;
- 选择第二个基模型, 重复上述2-4的步骤,可以得到第二个基模型对train和test数据集的一个stacking转换;
以下两张图描述的就是stacking的过程: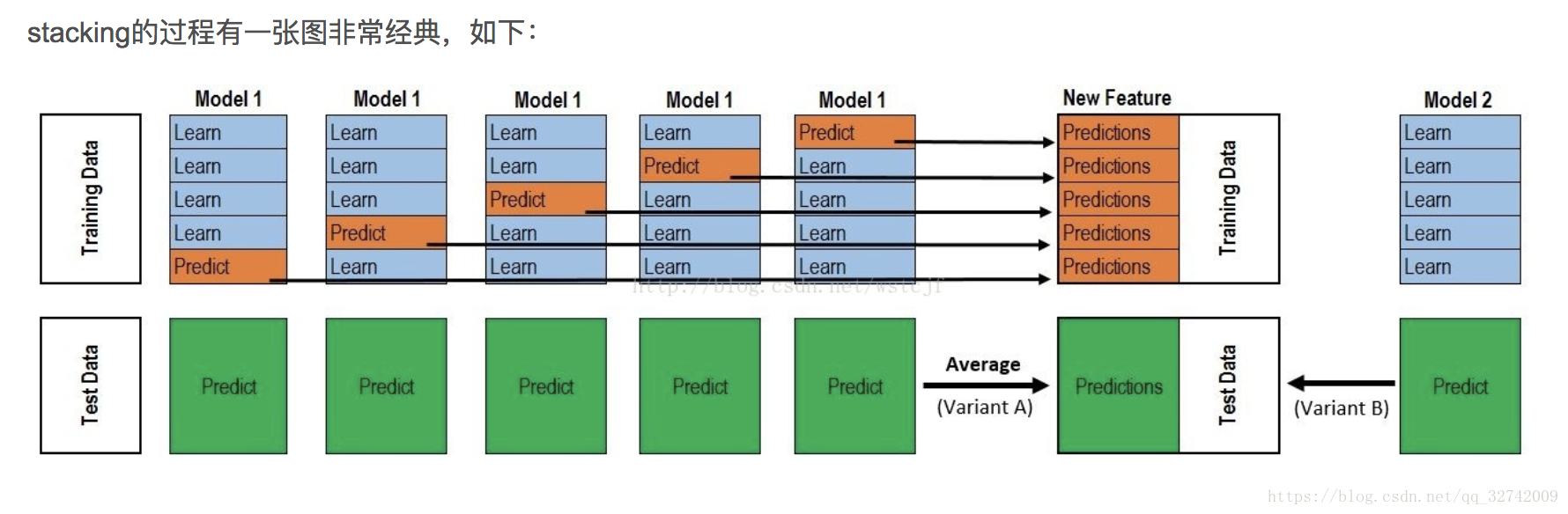
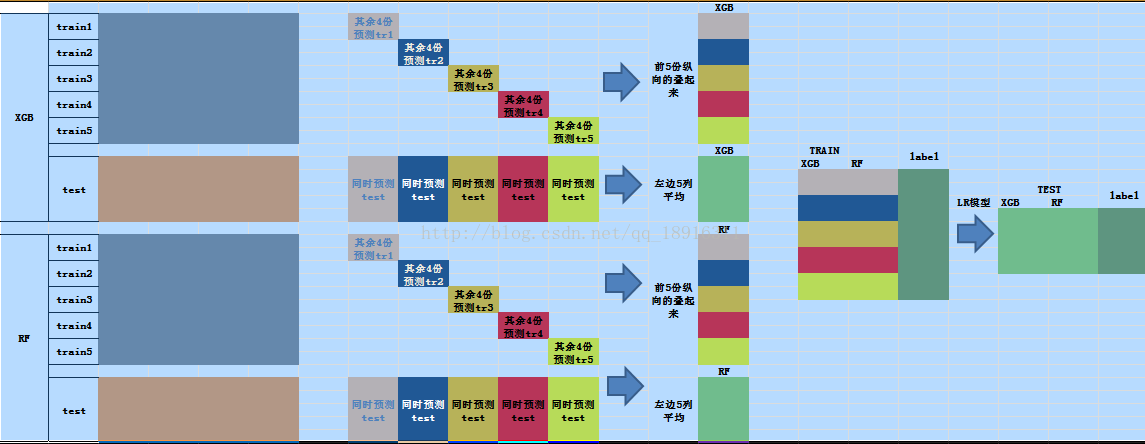
上图表示使用XGBoost和random forest模型进行stacking的过程,使用5折交叉验证,
对于数据集train和test(假设train的长度为N,test的长度为M),XGB和RF都可以将其重新表达得到新的train和test(都只有一列),因此有两份train和test的stacking转换,而train和test都是含有标签的,因此新的train是一个N行两列的数据,标签为N行一列,新的test是一个M行两列的数据,标签为M行一列,对于新的train和新的test,让下一层的模型基于这些数据进行训练;
也可以在第二层使用一个LR(logistic回归)模型基于新的train和新的test进行训练。